Human-Ape DNA Similarity Refuted: The 98.8% Genetic Similarity Claim Examined
Falsifying the Genetic Similarity Between Humans and Apes
In the name of God, the Most Gracious, the Most Merciful
However, before we begin, let us clarify the difference between genetic homology and genetic similarity, so that some of our brothers who work in the field of dawah do not get confused.
Table of Contents
- Genetic Homology vs Genetic Similarity
- The Mouse Example
- Is Human-Ape Genetic Similarity Really 98.8%?
- The Circular Reasoning Problem
- Bioinformatics and Functional Genomics
- The Robbery Analogy
- The 3 Million Base-Pair Sample Problem
- Deleting 35 Percent of the Genome
- The Problem of Insertions and Deletions
- Nature 2005 and the 600Mb Exclusion
- Science Magazine Exposes Humanized Bias
- Studies Giving Different Similarity Percentages
- Does Genetic Similarity Prove Evolution?
- Caterpillar and Butterfly Example
- Body Cells Example
- Sources
- Final Note
Genetic Homology vs Genetic Similarity
-
Genetic homology: means the presence of genes in one organism and a similar one in another organism, and it is not necessary to be subordinate.
-
Genetic similarity: is a specific sequence of genes in one organism and the presence of a similar one in another organism.
Rather, this percentage is for genes that have a counterpart in humans.
The Mouse Example
“On average, the protein-coding regions of the mouse and human genomes are 85% identical; some genes are 99% identical, while others are only 60% identical. These regions are evolutionarily conserved because they are required for function. In contrast, non-coding regions are less similar (only 50% or less).” [1], [2]

The scan supports the article’s distinction: homology means that a gene has a counterpart or comparable gene in another organism, while sequence similarity means that the actual genetic letters or base sequence are identical or highly similar. The article uses this distinction to argue that evolutionists often present percentage claims in a misleading way, making the public think entire genomes are almost identical when the claim may only concern selected comparable regions.

This matters because the article is warning against sloppy percentage claims. A high percentage in one selected category does not mean the entire genome has that same level of similarity. The scan is used to show that genetic similarity depends heavily on which part of the genome is being compared, and whether the comparison is between coding regions, non-coding regions, homologous genes, or full sequence alignment.
Is Human-Ape Genetic Similarity Really 98.8%?
Is there really a genetic similarity — almost identical gene sequence — between humans and monkeys that reaches98.8%, as they claim?
🪫 Evolution is true because evolutionists say so.
The Circular Reasoning Problem
Evolutionists presuppose in their arguments that evolution is true, such as this statement in the internationally recognized textbook on genetics, Bioinformatics and Functional Genomics, which is taught in universities:
🪫 “Two genes or proteins are similar if we consider that they evolved from a common ancestor.” [3], [4]
This is circular reasoning, because they presuppose that evolution did indeed occur from a common ancestor.
Bioinformatics and Functional Genomics
Even more astonishing is that the international textbookBioinformatics and Functional Genomics states that there are comparison mechanisms built on the same basis, and even software itself is built on it. [5]
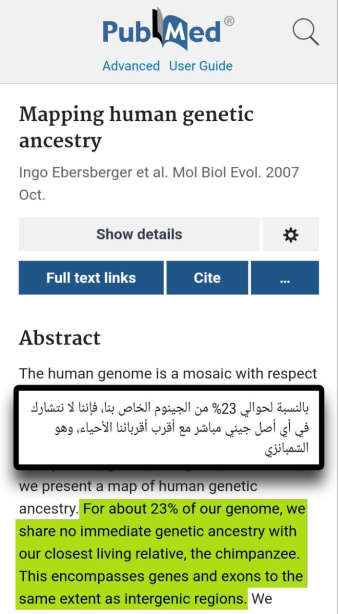
The article’s argument is that this definition already assumes the evolutionary framework before the comparison begins. In other words, if genes are labelled “homologous” because they are assumed to descend from a common ancestor, then using that homology later as proof of common ancestry becomes circular.
The scan is being used to support the claim that the evolutionary assumption is built into the terminology itself. The author is not merely objecting to genetic comparison, but to the way the comparison is framed from the beginning.

The key point is not simply that computers compare DNA. The article’s criticism is that the interpretation of similarity is shaped by an evolutionary model from the beginning. So when the results are later presented as proof of evolution, the author sees it as begging the question: the conclusion was already built into the method.
The Robbery Analogy
If I told you there was a bank robbery, and someone came and claimed I robbed the bank, then didn’t provide evidence to prove this claim, but assumed in advance that I was the one who robbed it, and informed the police.
When they came to investigate, they accepted his statement because he was the one who made the claim.
When they asked him for the evidence, he replied:
“I am the evidence.”
This is what I want to say.
Although the matter is illogical and the story is illogical, the followers of evolution did the same thing, as we explained, and as we will explain now…
The 3 Million Base-Pair Sample Problem
They took about 3 million nitrogenous base pairs, knowing that the number of bases in chimpanzees is about 3 billion nitrogenous bases.
What did they do next?
They found that two-thirds of the sample matched the analysis, and then what?
They found that 28% of the genetic sequence contained sequences belonging to unknown species.
Deleting 35 Percent of the Genome
Absolutely not.
They even removed 7% of the chimpanzee sequences because they were not similar to those in humans.
🪫 Imagine that they deleted 35% of the genome; and they even put this data into the BLAT program, which originally assumed the validity of evolution, as we explained above… [6].
If we asked them what right they have to delete these non-identical genes, they would answer:
🪫 “Because evolution happened.”
At that point, you realize that you are not dealing with scientists, but with a group of clowns who made those calculations.
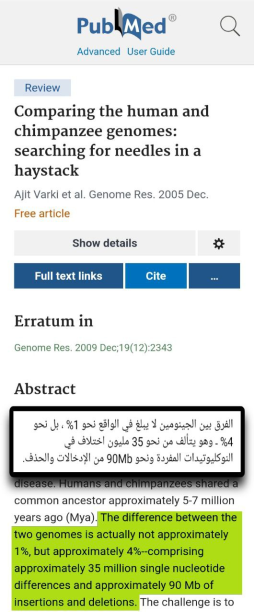
Instead, the article claims that researchers selected, excluded, filtered, or aligned data in a way that increased the final similarity percentage. The criticism is that parts of the chimpanzee genome that did not align well with the human genome were removed or treated separately, while the more similar regions were emphasized.
The scan supports the article’s accusation that the famous percentage depends on methodology. The author argues that if large unmatched or unknown portions are excluded, then the final number is not an honest full-genome similarity figure, but a result shaped by selective comparison.
The Problem of Insertions and Deletions
All of this happened by chance and did not lead to useless functions, as we explained in the article on junk genes.
These mutations, which they claimed were useless and arose as a result of evolutionary processes, are actually useful.
But we ask again:
What right did you assume that deletions and insertions actually occurred to include them in the programming?
How, for example, can 65 nitrogenous bases be inserted into the chain by mistake, without causing any errors or destroying the chain, all by chance?
And what right did they have to make a prior assumption?
🪫 This is circular reasoning in a nutshell.
Nature 2005 and the 600Mb Exclusion
In 2005, Nature published a comparison of genetic similarity; [7]
But before that, how big is the human genome?
It is about 3 billion base pairs.
What did the researchers do in the Nature study?
🪫 They eliminated about 600Mb of about 3Gb, leaving only 2.4Gb to analyze.
To give the best percentage of genetic similarity…
Didn’t I tell you that you are dealing with clowns?
Imagine that these studies are not based on:
- Did evolution occur?
Rather, they are based on:
- How did evolution occur?
As an axiom from the beginning, so they falsified it to give a higher percentage of similarity, and this is the fallacy of begging the question.

The key point being made is that if hundreds of megabases are excluded from comparison, the resulting percentage cannot be presented to the public as a simple whole-genome identity figure. The scan supports the argument that the final similarity number depends heavily on what is included and what is excluded.
The author uses this to claim that the famous human-chimpanzee similarity percentage is methodologically shaped, not a raw, neutral count of every base in both genomes.
Science Magazine Exposes Humanized Bias
🔬 ★ The tragedy is thatScience magazine exposed what they did, and said that there was a bias in the analysis, as it stated:
“High-quality human genome assemblies are often used to guide the final stages of non-human genome projects, including the order and orientation of sequence directions, and perhaps most importantly, the annotation of genes. This bias significantly ‘humanizes’ other genome samples.” [8]

The article emphasizes the phrase that this process can “humanize” other genome samples. The meaning is that if the human genome is used as the reference framework, then the resulting non-human genome may appear more human-like than it would under a fully independent assembly.
The scan is important because it supports the article’s claim that genome comparison can contain methodological bias. The author uses it to argue that some human-ape similarity claims may be inflated because the non-human genome is assembled or interpreted through a human reference model.
Studies Giving Different Similarity Percentages
📊 ★ A pro-evolution study came in 2005, stating that the difference should not be 1%, as they concluded, but 4%. [10]
📊 ★ Another study in 2007, after the forgery in 2002 and 2005, stated that the similarity was 77%, meaning that the difference rate was 23%. [11]
📊 ★ In a recent study in 2013, in which they did not forge the analysis, they stated that the similarity rate was 70%. [12]

The scan supports the point that different methods, data selections, and definitions of “similarity” can produce different results. The article uses this to challenge the simplistic public claim that humans and apes are “98.8% genetically identical.”

The significance is that even within evolutionary literature, the exact percentage is not always the simplistic 1.2% difference / 98.8% similarity often repeated in popular debates. The author uses this to argue that public evolution arguments rely on a simplified and inflated figure.
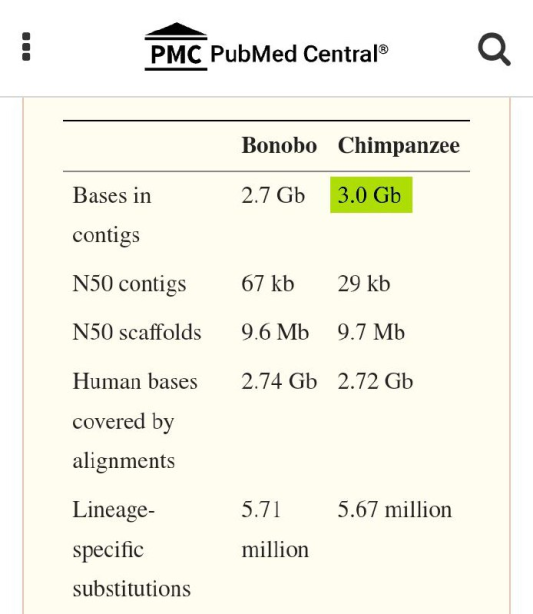
The scan supports the article’s final accusation that the famous 98.8% claim is not an honest full-genome number. The author uses it to argue that when excluded regions, unmatched sequences, insertions, deletions, and broader genome differences are taken seriously, the similarity percentage drops dramatically.
Does Genetic Similarity Prove Evolution?
❓ Does genetic similarity really indicate evolution?
Caterpillar and Butterfly Example
However, the caterpillar is one thing and the butterfly is another.
When the caterpillar is in the cocoon, it completely decomposes, and then emerges as a butterfly after complex processes inside the cocoon, meaning that the exact same DNA results in two different organisms.
🪲 So is the worm — larva — like the butterfly?
Body Cells Example
However, skin cells, for example, are not like brain cells.
Therefore, the article argues that genetic similarity by itself cannot be treated as automatic proof of common ancestry.
Sources
[2] https://www.genome.gov/10001345/importance-of-mouse-genome
[3]
[6] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC379137/
[7] https://www.nature.com/articles/nature04072
[8] https://www.science.org/doi/10.1126/science.aar6343
[9] https://pubmed.ncbi.nlm.nih.gov/12368483/
[10] https://pubmed.ncbi.nlm.nih.gov/16339373/
[11] https://pubmed.ncbi.nlm.nih.gov/17660505/
[12] https://answersresearchjournal.org/chimpanzee-and-human-chromosomes/
Final Note
This is the most reliable study I’ve read on comparing genetic similarity.